
Padrões de projeto em Aprendizado de Máquina: representando palavras e a intuição por trás dos Embeddings.
Introdução
[editar | editar código-fonte]Em tarefas de Machine Learning, a qualidade do modelo depende fortemente da qualidade do dado de entrada ou, popularmente, "Garbage in, garbage out". Embora esta frase se refira mais comumente a problemas de natureza estatística, como distribuições enviesadas não representativas da população em estudo, dados de baixa qualidade em termos de ruído, ou mesmo conjuntos que simplesmente não tem a informação adequada, ela vale também para problemas de representação de dados em relação a estrutura.
Representar os dados adequadamente é importante, especialmente em termos de dimensionalidade e nível de informação, pois esses fatores influenciam diretamente os custos de treinamento e podem até inviabilizar certas tarefas de serem executadas ou aprendidas.
Dito isso, queremos explorar uma questão central: como representar palavras semanticamente?
Relacionadas a essa pergunta, também vamos explorar: Como podemos representar dados categóricos para alimentar um modelo de Machine Learning? Como representar a semântica das palavras? E se for um vocabulário com 100 mil entradas? Quais são os trade-offs associados? E o que padrões de projeto tem a ver com isso tudo?
O que são Padrões de Projeto (ou Design Patterns)?
[editar | editar código-fonte]São soluções típicas para problemas recorrentes em projetos de software. Elas existem em um nível mais conceitual para permitir adaptação aos detalhes do seu problema. Padrões de projeto não são algoritmos, embora sejam usadas para construir soluções para problemas conhecidos, as implementações podem variar bastante.
O livro Machine Learning Design Patterns traz alguns desses padrões de projeto de forma organizada, agrupando-os nas classes:
- Representação de dados
- Representação de problema
- Treinamento de modelo
- Serviço resiliente
- Reprodutibilidade
- IA responsável
- Padrões conectados
Voltando à questão... Como representar palavras?
[editar | editar código-fonte]Hoje iremos entrar um pouco mais na parte de representação de dados e um padrão relacionado.
Vamos começar com um problema relaxado, uma abordagem inicial.
Como representar dados categóricos?
[editar | editar código-fonte]Vamos usar o problema de [classificação de espécies de Iris](https://www.kaggle.com/datasets/uciml/iris).
Esse dataset (bem famoso) é composto por métricas relativas às características das flores e o seu rótulo final (nome da espécie). No caso, precisamos representar adequadamente as categorias de saída:
- "Iris-setosa"
- "Iris-versicolor"
- "Iris-virginica"
Modelos de Machine Learning não são adequados para trabalhar com string diretamente, então uma abordagem inicial e ingênua seria atribuir um inteiro para cada um desses valores.
Digamos,
- "Iris-setosa" -> 0
- "Iris-versicolor" -> 1
- "Iris-virginica" -> 2
Essa é definitivamente uma abordagem, mas ela incorpora a informação de ordem na sua repesentação, que nem sempre é desejável para o problema que estamos trabalhando. Adotar essa forma no caso em questão insere, por exemplo, a informação de que "Iris-virginica" é maior que "Iris-versicolor", que é maior que "Iris-setosa".
Outra característica dessa abordagem é que ela implicitamente assume que as variáveis em estudo não são independentes. Novamente isso nem é sempre desejável para o problema.
One Hot Encoding
[editar | editar código-fonte]Uma outra abordagem muito comum para resolver esse problema é o One Hot Encoding. Ao invés de usarmos um único valor para representar, usaremos a quantidade de categorias em questão representar o dado, atribuindo 1 na posição referente a ela:
- "Iris-setosa": [1, 0, 0]
- "Iris-versicolor": [0, 1, 0]
- "Iris-virginica": [0, 0, 1]
Essa é a abordagem mais simples de representar variáveis independentes, mas requer conhecer previamente o vocabulário inteiro.
Várias bibliotecas em python já possuem implementações dessa representação:
- Scikit-learn : (https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html)
- pytorch : (https://pytorch.org/docs/stable/generated/torch.nn.functional.one_hot.html)
- tensorflow :(https://www.tensorflow.org/api_docs/python/tf/one_hot)
E se precisarmos representar por exemplo 20 mil palavras? ou 200 mil? ou uma língua inteira?
[editar | editar código-fonte]Nesse caso vetores com muitas entradas deixam de fazer sentido por serem esparsos (muitos zeros), e não adequados para vários modelos de machine learning existentes.
Além disso, o One Hot Encoding trata as entradas como variaveis independentes, que não é interessante no caso de vocabulários muito grandes (é útil que palavras parecidas ou sinônimos tenham correlação).
Por fim, a necessidade de conhecer o vocabulário inteiro impede de representar palavras totalmente novas ou neologismos.
Embeddings
[editar | editar código-fonte]Há um padrão de projeto que permite resolver todos os problemas citados: O embedding.
O que são Embeddings?
[editar | editar código-fonte]São vetores numéricos aprendíveis que representam os dados. Eles mapeiam dados de alta cardinalidade em um espaço dimensionalmente menor (menos bytes), destilando a informação dos dados originais. Em geral é esperado que a medida de distância entre vetores de dados similares sejam menores do que a de vetores com dados dissimilares.
Como são criados embeddings para palavras?
[editar | editar código-fonte]- Em linhas gerais: string -> token -> embedding
- Existem algumas técnicas para gerar word embeddings:
- Frequency-based embeddings (tf-idf, co-occurence matrix)
- Prediction-based embeddings (word2vec, FastText, GloVe)
- Na prática dá pra usar plataformas prontas com embeddings prontos (kaggle, hugging face, ...)
Características importantes
[editar | editar código-fonte]Ao analisar os vetores embeddings de palavras são observados alguns efeitos:
1) Proximidade semântica
[editar | editar código-fonte]A distância euclidiana (ou alguma outra medida de distância) entre dois vetores provê uma boa métrica de proximidade semântica.
fonte: https://projector.tensorflow.org/
2) Subestrutura Linear
[editar | editar código-fonte]Palavras com mesma relação entre si tendem a preservar posicionamento relativo parecido.
Veja a seguir alguns exemplos e suas relações (https://nlp.stanford.edu/projects/glove/):
- (https://nlp.stanford.edu/projects/glove/images/company_ceo.jpg) relação: companhia-ceo
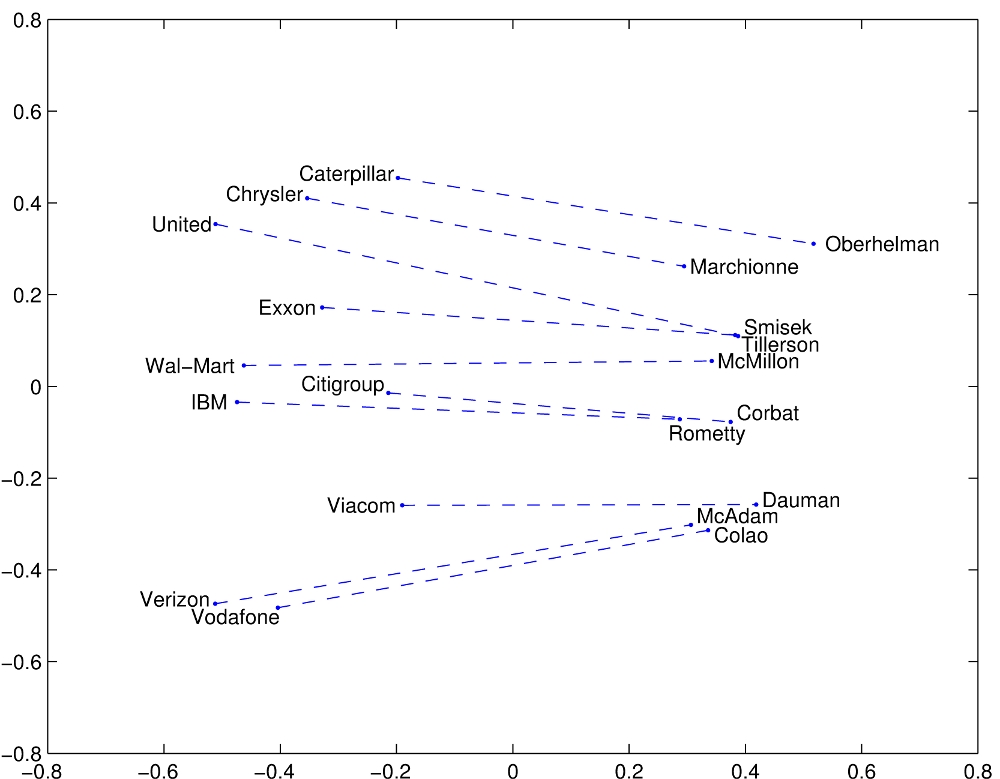{kind=link}
- (https://nlp.stanford.edu/projects/glove/images/comparative_superlative.jpg) relação: comparativo-superlativo
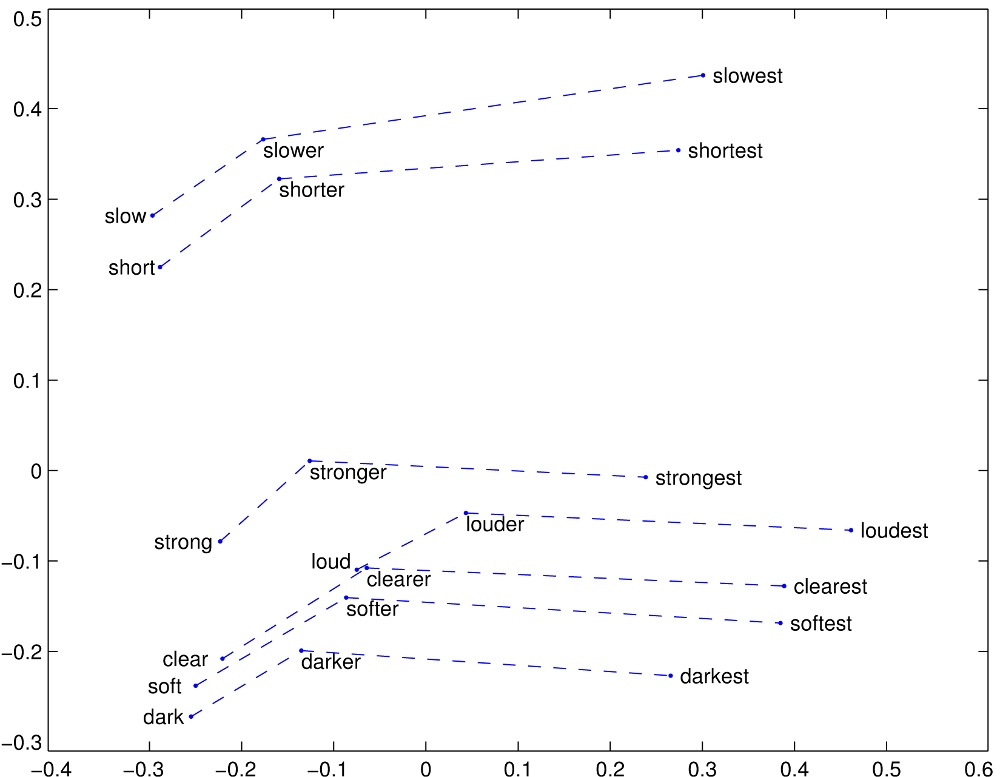{kind=link}
- (https://nlp.stanford.edu/projects/glove/images/man_woman.jpg) relação: homem-mulher
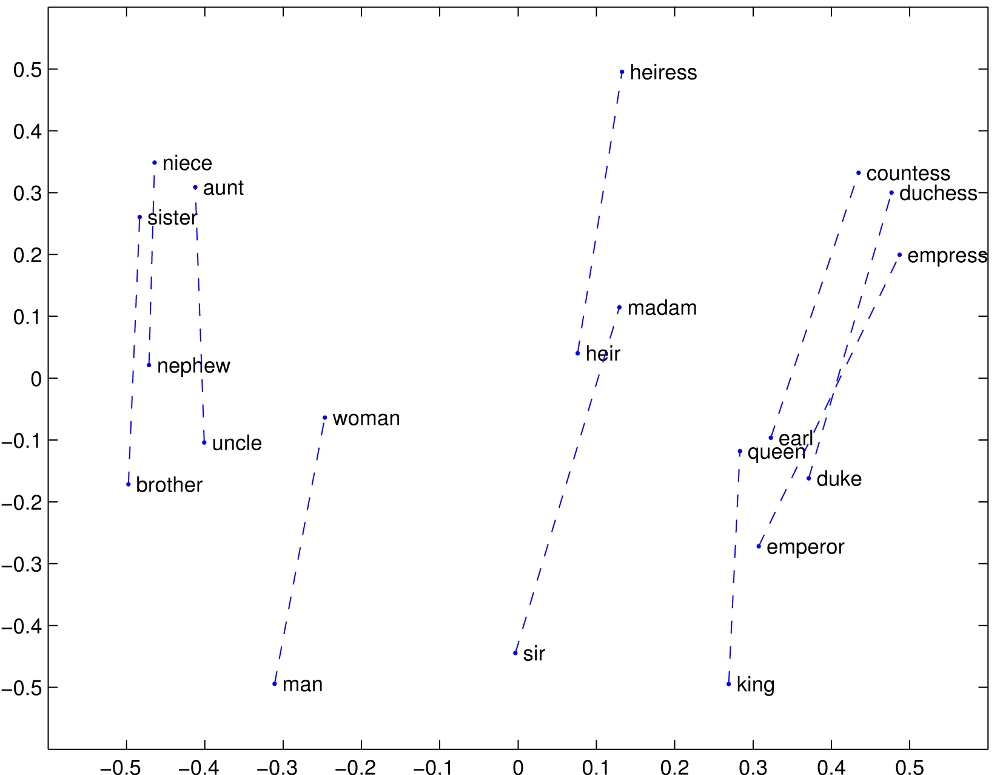{kind=link}
Representação contextual
[editar | editar código-fonte]E se tivermos as duas frases a seguir?
- Precisava fazer um banquete, então cortou a sua manga.
- Precisava fazer um torniquete, então cortou a sua manga.
A palavra manga tem a mesma grafia, mas os significados são diferentes com a mudança de contexto.
Contexto Importa
[editar | editar código-fonte]Para resolver essa questão existem algumas abordagens como algoritmos de Self-Attention, que consistem em bastante álgebra linear e não vamos entrar no detalhe nesse artigo.
Essa também é a ideia central por trás da arquitetura de Transformers e o grandes modelos de linguagem, incluindo o ChatGPT.
Se tiver interesse em saber mais sobre embeddings contextuais, disponibilizamos uma lista de materiais recomendados ao final do post.
Conclusão
[editar | editar código-fonte]Machine Learning possui os seus próprios problemas recorrentes em que Padrões de Projetos podem ser aplicados. A qualidade da representação dos dados é uma delas e hoje exploramos um pouco sobre algumas questões relacionadas a isso, estudando desde representações categóricas até os poderosos Embeddings Vetoriais, os problemas que eles resolvem e algumas de suas limitações.
Referências e links recomendados
[editar | editar código-fonte]Links recomendados:
- Intuition behind attention mechanisms - Ark
- Visualizando a atenção, o coração de um transformador - 3 Blue 1 Brown
Referências:
- Machine learning Design Patterns O'reilly
- https://refactoring.guru/design-patterns/what-is-pattern
- dataset Iris
- Word Embedding Analogies: Understanding King - Man + Woman = Queen
- 5 Types of Word Embeddings and Example NLP Applications
- Dive into deep learning: Word embeddings
- Embeddings Projector
- GloVe
- Attention is all you need
- Word Embeddings: A Survey